How to get audience insights for free using the Reddit API
Using a Python script to collect posts which are then analysed by ChatGPT.

Social listening (trawling through Facebook, Instagram, TikTok and so on to find insights) is a method more commonly associated with brand and market research than UX research.
UX researchers typically conduct desk research to inform their work and might look at social media as part of this, but social listening isn’t really a primary method compared to qual interviews, surveys and so on.
The main reason for this is access to tooling. Most UX research teams don’t have paid accounts for platforms like Brandwatch and Sprinklr, making social listening a laborious task that they can’t do at any level of scale or rigour.
Free social listening data sources
If getting a paid social listening tool isn’t on the horizon, then there are a few options you can use. All social media platforms have APIs and some are more open than others.
I got ChatGPT deep research to document public data sources and their free tier limits, which you can read here if you want. In summary, Reddit is the most generous and useful source, because it has millions of users discussing a wide variety of topics, and it takes a lot before you hit the limits of their free tier.
Building a script to query the Reddit API
Having identified the Reddit API as the best source of free social listening data, I got ChatGPT to help me vibe code a simple Python script that would query it and return the results in a file.
With the magic of AI, we can then take a file with thousands of Reddit posts and use ChatGPT deep research to analyse it.
For the sake of this post, I’ll skip over the process of using ChatGPT Codex and VSCode to write the Python script, but the process was similar to my recent post about vibe engineering.
Using my Python script which queries the Reddit API
If you’d like to try out the script, you can find it on GitHub here.
There’s full documentation in the link above, but let’s walk through a simple use case.
First, download the reddit-pull.py file.
Open it in TextEdit or any other code/text editor and go to line 34. Here you’ll see some variables you need to update with your own name:
APP_OWNER_HANDLE = "philmorton"
APP_OWNER_REDDIT_USERNAME = "philipmorton"
APP_VERSION = "0.1"
DEFAULT_OUTPUT_DIRECTORY = "/Users/philipmorton/Downloads"
DEFAULT_OUTPUT_FILENAME = "reddit_results.jsonl"
Once you’ve updated the file, open up the Terminal in the directory where you’ve saved it.
You’ll need to make sure you have Python and ‘requests’ installed for it to work. I recommend using ChatGPT to help you with this if identify as ‘non-technical’!
Once you’re set up, then we can use the script to do one of three things:
- Search all of Reddit for a keyword
- Pull every recent post from a subreddit
- Search within a subreddit
It will then output a JSON file with the posts and a .manifest.json file which describes what happened when you ran the script.
An example query
Let’s imagine that we’re helping Sports Interactive respond to the recent launch of Football Manager 26. We know that our audience uses Reddit and we can see there’s an active subreddit. We want to collect all of the posts from this subreddit in the last month.
In the Terminal, we’d write the following:
python3 reddit-pull.py --subreddit footballmanagergames --time month
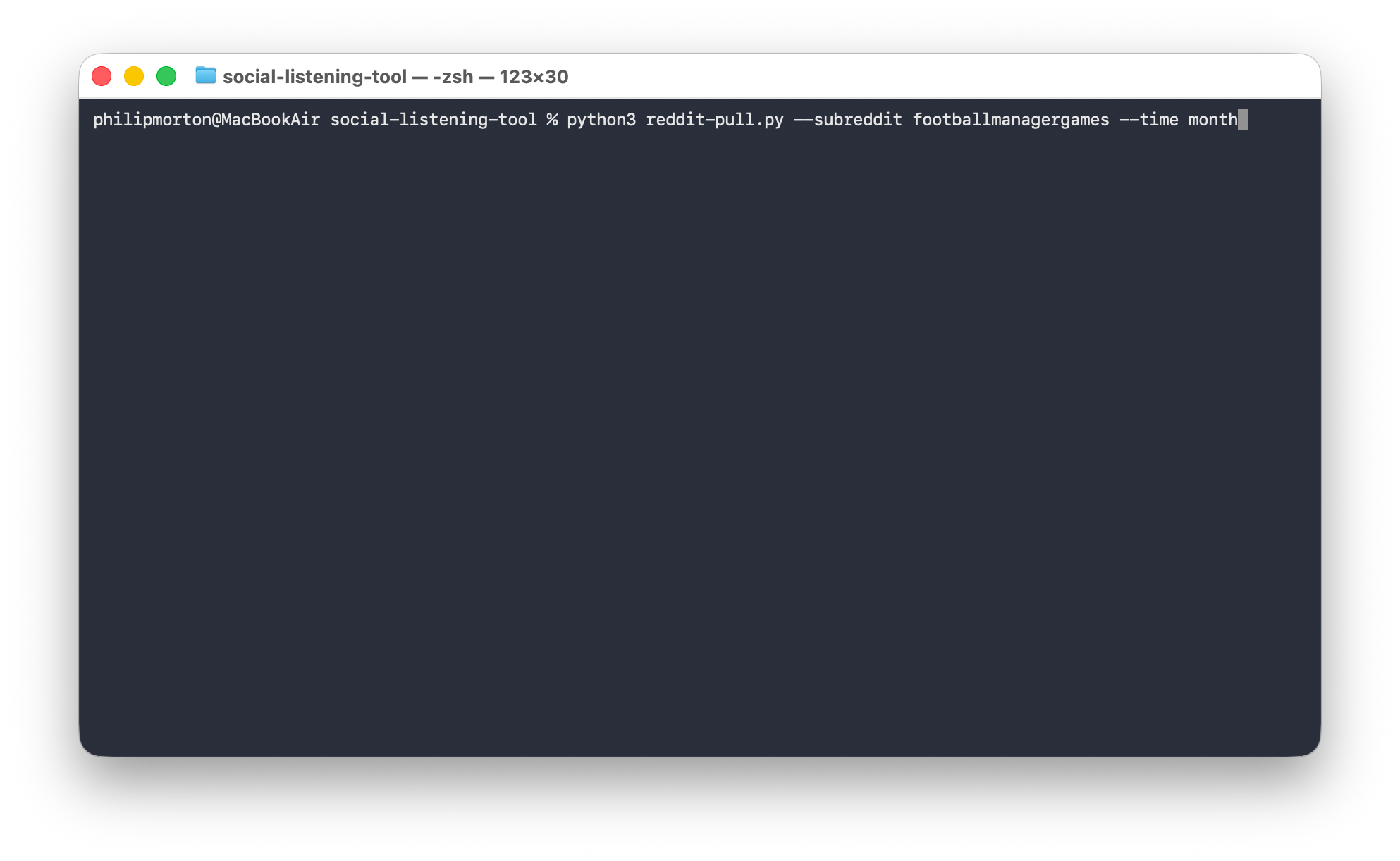
By default, it will attempt to get up to 5000 posts. The script is also written in a way that it will stay under the free tier query limit.
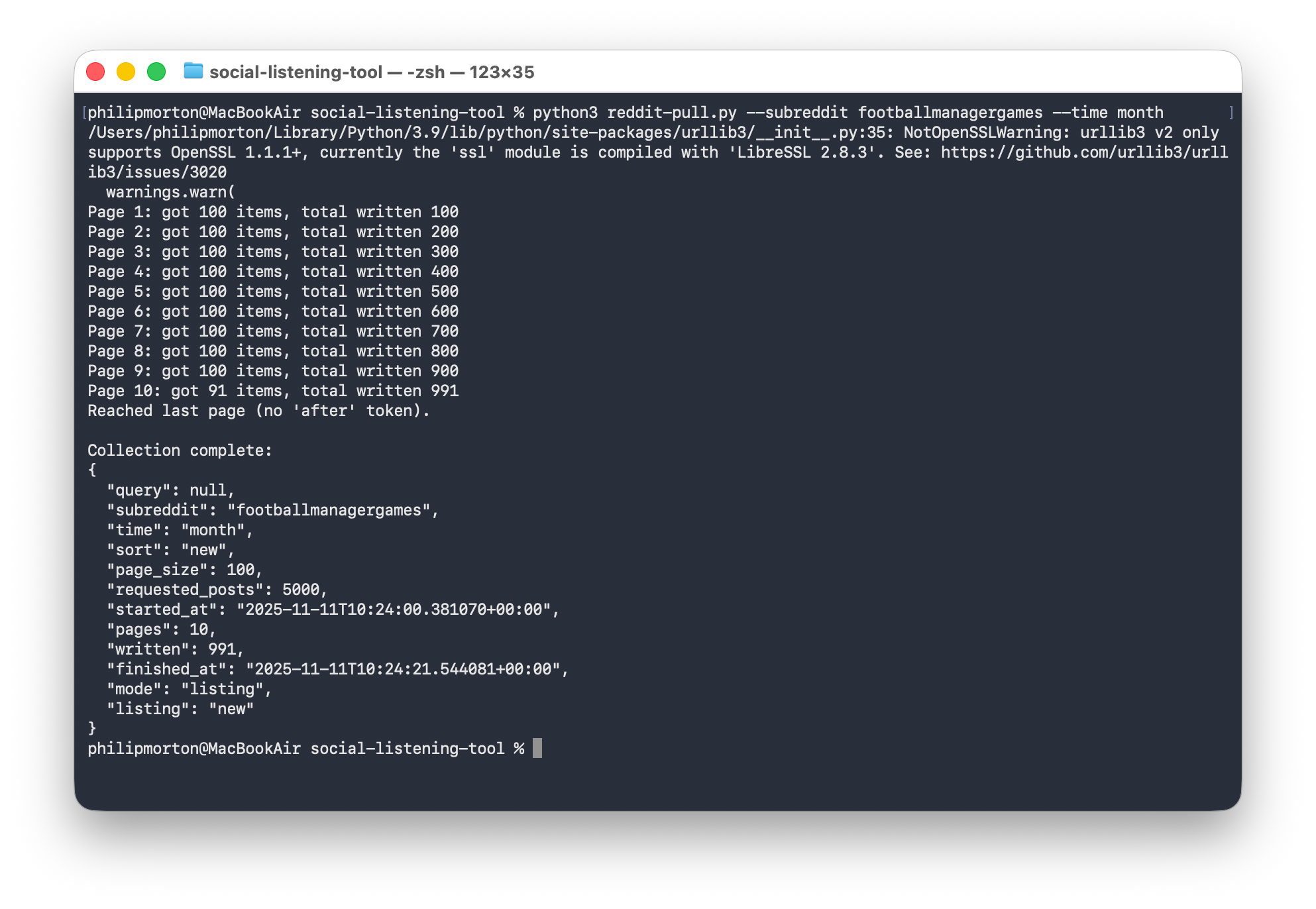
In this example, it found 991 posts in the last month and wrote them to a file for us:

Analysing the results with ChatGPT deep research
Now we need to make sense of these posts. Open up ChatGPT (or your favourite LLM) and prompt something like this:
### **Role**
You are a data analyst specialising in qualitative research and social listening. Your task is to review and interpret Reddit data exported from a custom Python script. The data represents posts and/or comments pulled via the Reddit API in JSON format.
---
### **Context**
The JSON file contains public Reddit posts and comments about Football Manager 26 from a subreddit.
Each item typically includes fields such as:
* `title` (string): Post title
* `body` or `selftext` (string): Main text content
* `subreddit` (string): Community name
* `score` (integer): Upvotes
* `num_comments` (integer): Number of comments
* `created_utc` (timestamp): Post date/time
* `author` (string): Poster username (sometimes “deleted”)
The goal is to identify key **themes, sentiments, trends, and outliers** in how people discuss the topic.
---
### **Task**
1. Load and interpret the JSON file contents.
2. Identify **dominant discussion themes** (recurring ideas, keywords, or concerns).
3. Provide **illustrative quotes** (short excerpts) that exemplify each theme.
4. Analyse **sentiment** (positive, negative, neutral) and provide a rough distribution.
5. Highlight **anomalies or unexpected insights** (e.g. a post framing the topic in a surprising way).
6. Conclude with a concise **summary of the overall discussion**, including:
* What people care about most
* How opinions differ across groups
* The general tone or mood of the conversation
---
### **Guidelines**
* Focus on meaning rather than raw counts; this is a qualitative thematic analysis.
* Treat each post or comment as a text sample; short comments can still contribute to patterns.
* Use bullet points, short quotes, and concise section headings for readability.
* Avoid listing every post—summarise patterns and back them up with examples.
* If multiple subreddits are included, compare tone or focus between them.
* Use natural, narrative language rather than code or JSON.
* Include brief commentary when patterns contradict expectations or reveal unique perspectives.
It will then output a report for you like this:
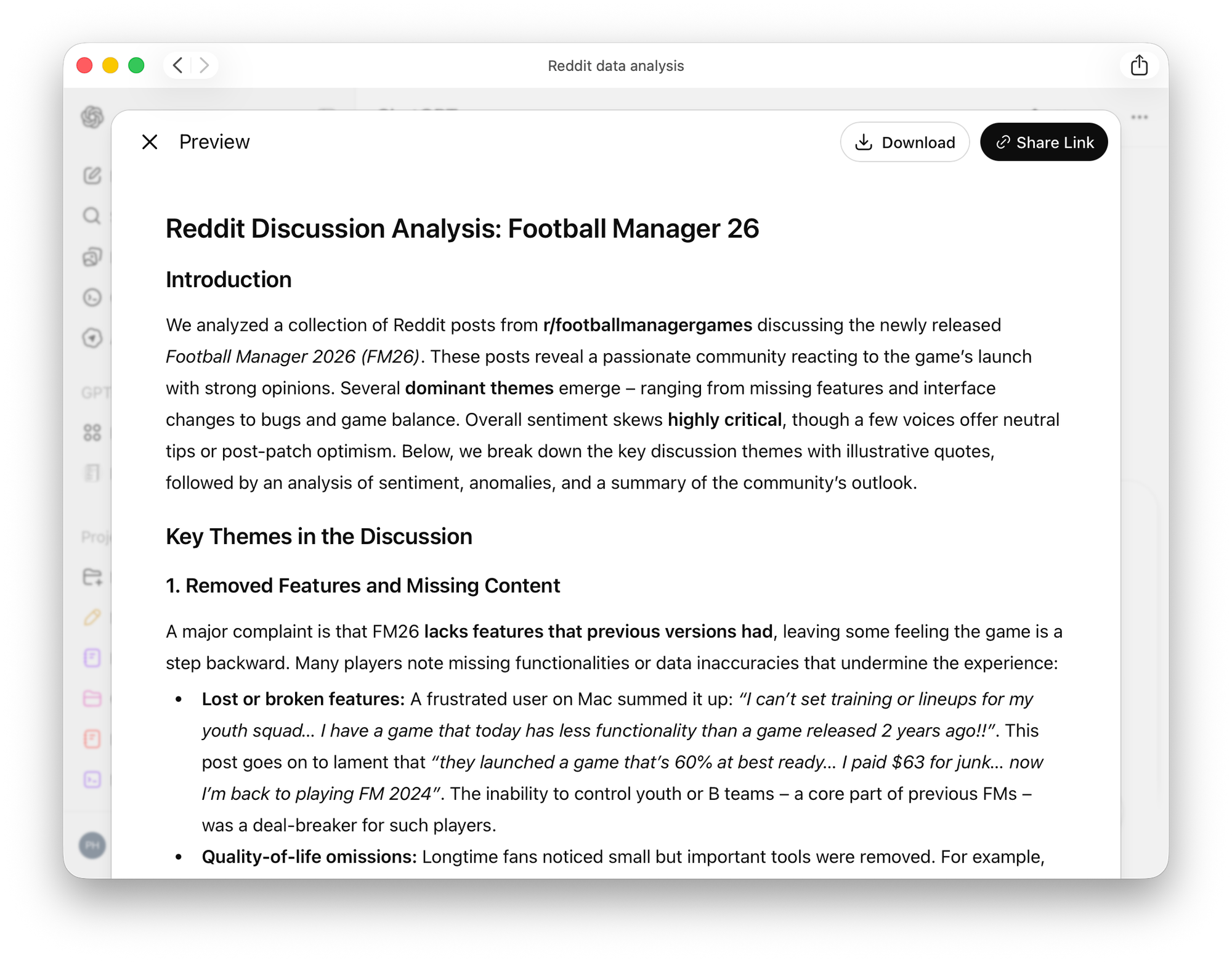
It’s not perfect but it’s free
Reddit is only one data source and it’s not suitable for every project, but you can’t argue with the cost!
If you’re a UX researcher, adding quantitative social listening data alongside other sources of evidence will add depth and richness to your insights.
What I’ve shared here is a tiny MVP for what could be a much broader tool. Imagine having a front-end UI and being able to connect other free public data sources. That’s a project for another day though...